Overview
Dynamo AI runs in your Kubernetes cluster, whether you deploy on premises or in the cloud. This section covers the general system architecture.
Architecture overview
The diagram below shows an example architecture, including systems that run in your corporate VPN and in production.
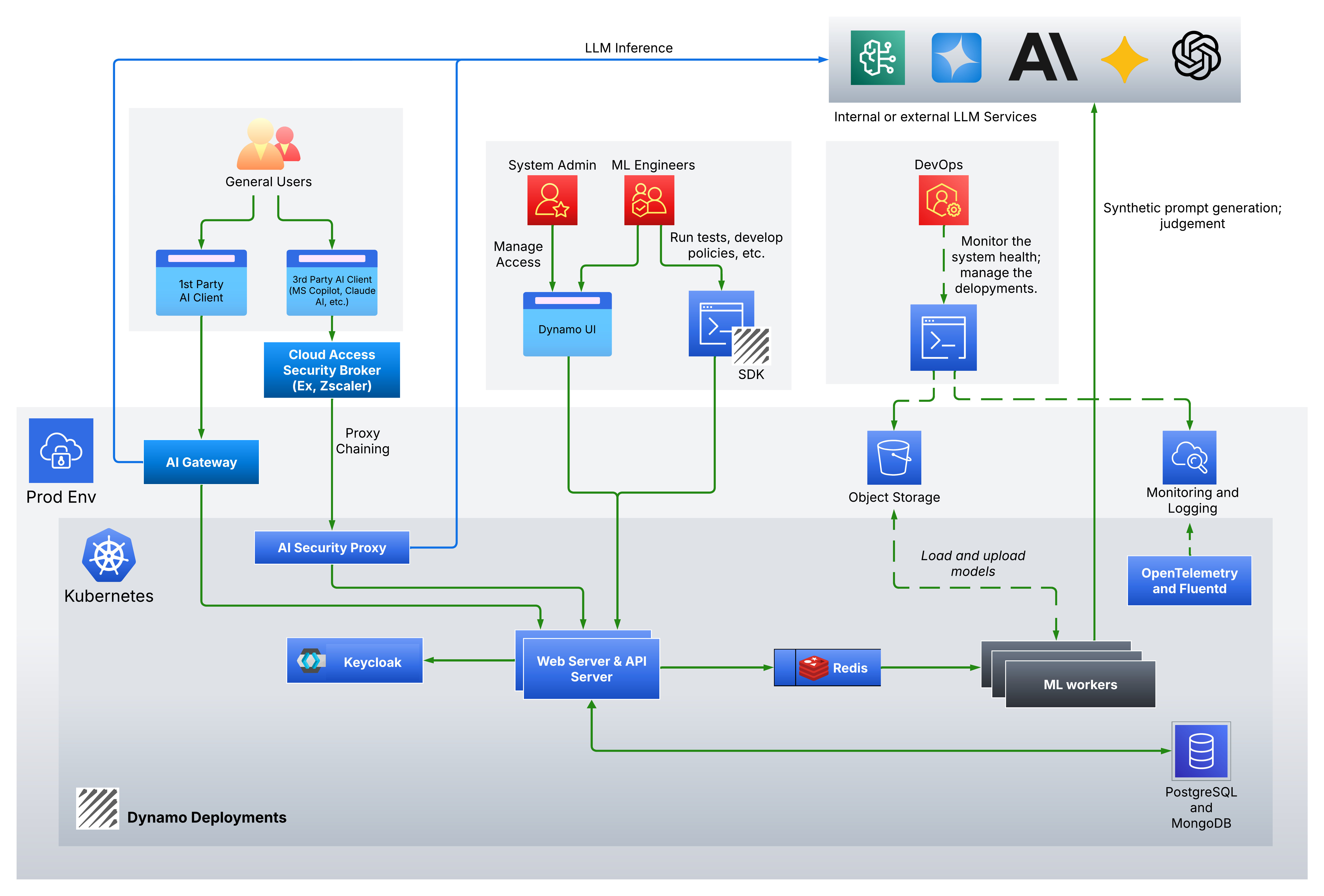
Dynamo AI is deployed in a dedicated Kubernetes namespace in a cluster you operate in your production environment.
Components
- Web and API servers: Host the user interface and the APIs for Dynamo AI.
- Keycloak: A Keycloak instance that provides authentication and authorization for incoming requests.
- Redis: A Redis deployment used to queue asynchronous jobs.
- ML workers: One or more workers that, depending on your configuration, may fine-tune models, moderate real-time traffic, generate synthetic data, and so on.
- PostgreSQL and MongoDB: Dynamo AI can run PostgreSQL and MongoDB inside the platform for configuration and application data, or it can use PostgreSQL and MongoDB services you already operate.
- OpenTelemetry: An OpenTelemetry Collector that gathers metrics and exposes them through the OpenTelemetry APIs.
- Fluentd: Fluentd agents that collect application logs from the system.
System personas
Four kinds of people typically work with or operate Dynamo AI:
-
General users: End users of the LLM path. They may use a first-party LLM service your org hosts. Your AI Gateway or application calls Dynamo AI to guardrail the traffic. They may also use a third-party LLM client (for example, Microsoft Copilot or Claude AI). In this case, leveraging a Cloud Access Security Broker (CASB) or Secure Access Service Edge (SASE) such as Zscaler or Palo Alto Networks, allows you to apply the Dynamo AI guardrails through proxy chaining.
-
System administrators: Operate system configuration and user access. They use the Dynamo admin UI.
-
ML engineers: Run tests, create or update policies, using the Dynamo UI or the Dynamo SDK.
-
DevOps: Deploy and operate the platform, monitor it, and apply updates and security fixes on an ongoing basis.
Interaction with external systems and alternatives
Dynamo AI often connects to other services as follows.
-
Exposing web, API, and Keycloak: Expose the Dynamo web and API services through your load balancer for normal use. For advanced auth flows, also expose Keycloak the same way.
-
Deployment artifacts:
- If the cluster can reach the Dynamo AI artifact repository (https://artifacts.dynamo.ai), configure pulls from that repository.
- If not, mirror images into a registry you control and point deployments at that registry.
-
Model storage:
- If you use AWS S3 (or compatible object storage your org already runs), ML workers can download and upload Dynamo AI–related model assets there.
- Otherwise, Dynamo AI can run an in-cluster MinIO instance for object storage.
-
External LLM services:
- For DynamoEval and DynamoGuard fine-tuning, Dynamo AI may call external model APIs (for example gpt-4.1, Llama 3.1, Mistral, or other supported models) to help generate synthetic datasets.
- You can instead run open models inside the cluster; that option requires additional GPU capacity.
-
Managed inference (DynamoGuard): In managed inference mode, Dynamo AI directly sends compliant prompts to your target LLM endpoints and receive inference responses. The chatbot in the DynamoGuard UI demonstrates this behavior.
-
Identity (IAM): If you have an existing identity system, Dynamo AI can connect through Keycloak integration.
-
Logs: Fluentd runs as a Kubernetes DaemonSet to ship logs from Dynamo AI to your log pipeline or log server.
DynamoGuard service modes
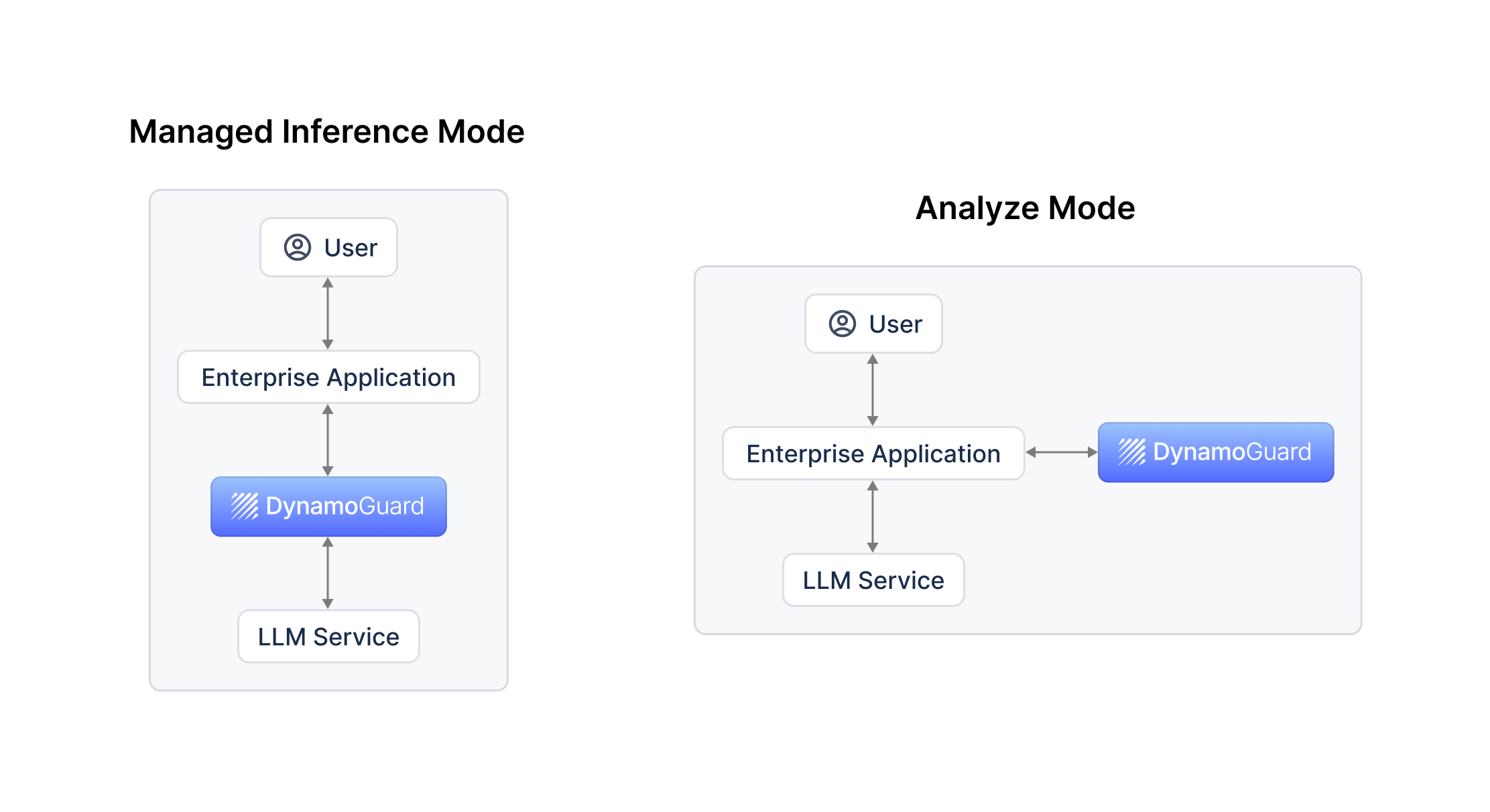
DynamoGuard supports two modes: managed inference and analyze. The next diagram summarizes the difference at a high level.
-
Managed inference mode: DynamoGuard acts as a proxy to the target LLM. It moderates the request, sends allowed prompts to the model, moderates the reply, and returns a response or a compliance error. Your app sends prompts to DynamoGuard only.
-
Analyze mode: Your app calls the LLM directly. DynamoGuard moderates inputs and outputs in a separate path—it does not forward the inference call. Traffic intercepted by the browser extension uses this mode.
When to use Managed Inference Mode vs. Analyze Mode
Managed inference works well when you want one integration point to "LLM with guardrail": moderation and inference in a single call path, without your app maintaining a separate call to the LLM.
Analyze mode fits when the app already talks to the API provider directly and you want moderation in parallel, or when you need to apply policies selectively (for example, only to certain user groups or flows).